HYBRID BOOK LAUNCH
Anna's AI Anthology. How to live with smart machines?
7 OCTOBER 2024, 8 pm (Berlin time)
Kino Babylon (Rosa-Luxemburg-Straße 30, 10178 Berlin) & online via Zoom
The book launch will include four small panel discussions in which 2 to 3 authors will briefly recall the main theses of their essays, discuss them with the other authors, and answer questions from the audience.

https://www.momo-berlin.de/veranstaltungen-detail-seite/book-launch-anna-s-ai-anthology-how-to-live-with-smart-machines.html
PRELIMINARY SCHEDULE [*all times are local Berlin time (CEST = UTC+02:00)]
Here you can easily check what time it is in other time zones: | https://www.timeanddate.com/worldclock/converter.html?iso=20240910T180000&p1=37&p2=179 |
time | topic | protagonists |
8.00 pm | Introduction & the genesis of the Anthology | Anna Strasser, Moritz Strasser, |
8.20 pm | PANEL 1: | Keith Frankish, Paula Droege, |
8.45 pm | PANEL 2: | Stephen Butterfill, Sven Nyholm |
9.10 | PANEL 3: | Henry Shevlin, Alessio Tacca, |
9.35 pm | PANEL 4: | Eric Schwitzgebel, Syed AbuMusab, Constant Bonard |
Together with the authors of Anna's AI Anthology, we will be celebrating the fact that in addition to the deluxe edition with the removable, color graphic novel, as an add-on, a paperback (black and white) and an electronic version (PDF) of the book will be available (probably on September 16th).
Hardcover: 978-3-942106-90-0 --> 38,20 €
Paperback: 978-3-942106-98-6 --> 34,00 €
PDF-Version: 978-3-942106-99-3 --> 28,00 €

The book can be ordered at the publisher's web shop by following this LINK
https://www.xenomoi.de/philosophie/momo-berlin-philosophische-kontexte/303/anna-s-ai-anthology.-how-to-live-with-smart-machines-editor-anna-strasser?c=1120
ON STAGE: THE BOOK, THE EDITOR, THE PUBLISHER, THE ARTIST OF THE GRAPHIC NOVEL AND AT LEAST 10 AUTHORS
*when you click on names the website of the person opens / tbc= to be confirmed
PANEL 1 | How to conceptualize the capacities of LLMs and characterize their behavior? | |
 Keith Frankish |  Paula Droege |  Joshua Rust |
PANEL 2 | The human perspective on LLMs: What may we infer about LLMs from the outputs they produce? | |
 Stephen Butterfill |  Ying-Tung Lin (tbc) |  Sven Nyholm |
PANEL 3 | Could LLMs be seen as a new kind of partner in social interactions? | |
 Eric Schwitzgebel |  Syed AbuMusab |  Constant Bonard |
PANEL 4 | What are potential implications of this new technology? | |
 Henry Shevlin |  Alessio Tacca |  Michael Wilby |
 Moritz Strasser |
TITLES & ABSTRACTS (alphabetical order)
Syed AbuMusab (University of Kansas): Large Language Models Belong in Our Social Ontology
The recent advances in Large Language Models (LLMs) and their deployment in social settings prompt an important philosophical question: are LLMs social agents? This question finds its roots in the broader exploration of what engenders sociality. Since AI systems like chatbots, carebots, and sexbots are expanding the pre-theoretical boundaries of our social ontology, philosophers have two options. One is to deny LLMs membership in our social ontology on theoretical grounds by claiming something along the lines that only organic or X-type creatures belong in our social world. Second, expand our ontological boundaries. I take the second route and claim LLMs implemented as social chatbots are social agents. Utilizing Brian Epstein's concepts of grounding and anchoring, alongside Dee Peyton's criteria for what makes a property social, I posit that the capacity for conversations is a social property. Further, within a framework where social agency is considered multi-dimensional, akin to agency, possessing a social property is sufficient for attaining social agency. Thus establishing chatbots as social agents. A helpful concept here is Levels of Abstraction (LoA). The LoA framework allows for extracting relevant and important information from the target domain (the social world). For example, the property of being a 'boy' and the capacity for conversation are social properties; hence, they are part of the social domain. LLMs have the capacity for conversations. So, if we focus on the conversational-LoA and not the gender-LoA, then LLMs occupy a dimension of sociality (i.e., conversational dimensions).
Constant Bonard (Institut Jean Nicod): Can AI and humans really communicate? The mental-behavioral methodology
To answer the question “Can AI and humans really communicate?” I propose to follow the following three steps – I call this the ‘mental-behavioral methodology’. First step: Spell out what mental capacities are sufficient for human communication (as opposed to communication more generally). Second step: Spell out or develop the experimental paradigms required to test whether a behavior exhibits these capacities. Third step: Apply or adapt these paradigms to test whether an AI displays the relevant behaviors. If the first two steps are successfully completed, and if the AI passes the tests with human-like results, this would indicate that AI and humans can really communicate. This mental-behavioral methodology cannot be achieved as of yet because the science required for the first two steps is not fully developed. But it is in principle achievable. It has the advantage that we don’t need to understand how “black box” algorithms work. This is comparable to the fact that we don’t need to understand how human brains work to know that humans can really communicate: we just observe each other’s behaviors to see (i.e. to test) if we have the sufficient mental capacities. I will also address some of the challenges posed by this methodology.
Butterfill, Stephen (Warwick University): What mindreading reveals about the mental lives of machines.
Which systems—artificial and biological—have mental lives of their own? Which possesses mental states like knowledge, belief or desire and have powers to imagine, remember episodes, understand propositions or mentally simulate counterfactual scenarios? Which are agents or even persons? Attempts to answer these questions can rely on commonsense, on philosophy or on science. In each case, the attempts are confronted by a series of problems. The purpose of this chapter is to identify those problems, and to present them in their most challenging forms. The chapter’s tentative conclusion is that the question about mental lives is misguided in roughly the way that questions about the impetus of a comet moving through a vacuum would be. As impetus is useful only when gravity and air resistance do not vary, so also notions like knowledge and understanding feature in frameworks that are useful in a limited range of social contexts only. This conclusion has implications for debates about theory of mind in large language models, and about the reasoning capacities of those systems. But, crucially, there is a way in which problems about the mental lives of artificial systems do not matter at all. Despite appearances, the most successful paradigms in cognitive psychology which use deep learning do not in fact rely on those systems knowing or understanding at all.

Daniel Dennett (Tufts University, Santa Fe Institute): We are all Cherry-Pickers
Large Language Models are strangely competent without comprehending. This means they provide indirect support for the idea that comprehension, (“REAL” comprehension) can be achieved by exploiting the uncomprehending competence of more mindless entities. After all, the various elements and structures of our brains don’t understand what they are doing or why, and yet their aggregate achievement is our genuine but imperfect comprehension. The key to comprehension is finding the self-monitoring tricks that cherry-pick amongst the ever-more-refined candidates for comprehension generated in our brains.
Paula Droege (Pennsylvania State University): Full of Sound and Fury, Signifying Nothing
Meaning, language, and consciousness are often taken to be inextricably linked. On this Fregean view, meaning appears before the conscious mind, and when grasped forms the content of linguistic expression. The consumer semantics proposed by Millikan breaks every link in this chain of ideas. Meaning results from a co-variation relation between a representation and what it represents, because that relation has been sufficiently successful. Consciousness is not required for meaning. More surprising, meaning is not required for language. Linguistic devices, such as words, are tools for thought, and like any tool, they can be used in ways other than originally designed. Extrapolating from this foundation, I will argue that Large Language Models produce speech in conversation with humans, because the resulting expression is meaningful to human interpreters. LLMs themselves have no mental representations, linguistic or otherwise, nor are they conscious. They nonetheless are joint actors in the production of language in Latour’s sense of technological mediation between goals and actions.

Keith Frankish (University of Sheffield): What are Large Language Models Doing?
Do large language models perform intentional actions? Do they have reasons for producing the replies they do? If we adopt an ‘interpretivist’ perspective, which identifies reason possession with predictability from the intentional stance, then there is a prima facie case for saying that they do. Ascribing beliefs to an LLM gives us considerable predictive power. Yet at the same time, it is implausible to think that LLMs possess communicative intentions and perform speech acts. This presents a problem for interpretivism. The solution, I argue, is to think of LLMs as making moves in a narrowly defined language game (the 'chat game') and to interpret their replies as motivated solely by a desire to play this game. I set out this view, make comparisons with aspects of human cognition, and consider some of the risks involved in creating machines that play games like this.
Ying-Tung Lin (National Yang Ming Chiao Tung University): The Fluidity of Human Mental Attribution to Large Language Models
Recent developments in Large Language Models (LLMs) made the nature of the relationships between users and LLMs an interesting area of research. This paper focuses on human mental attributions to LLMs. It seeks to determine if and how humans ascribe mental states to LLMs. Do users perceive LLMs as mere instruments or entities with some agency? If mental states are attributed, which specific ones are they, and how are they determined? I argue that the answers to these questions are less straightforward, and there is a lack of consistency among human users in these attributions. That is, we are fluid in mental attributions to LLMs.
Sven Nyholm (LMU Munich): Generative AI's Gappiness: Meaningfulness, Authorship, and the Credit-Blame Asymmetry
When generative AI technologies generate novel texts, images, or music in response to prompts from users of these technologies, are the resulting outputs meaningful in all the ways that human‐created texts, images, or music can be meaningful? Moreover, who exactly should be considered as the author of these AI outputs? Are texts created by generative AI perhaps best considered as authorless texts? In my paper, I will relate the above‐mentioned questions to the topic of who (if anyone) can take credit for, or potentially be blameworthy for, outputs created with the help of large language models and other generative AI technologies. I will argue that there is an important asymmetry with respect to how easily people can be praiseworthy or blameworthy for outputs they create with the help of generative AI technologies: in general, it is much harder to be praiseworthy for impressive outputs of generative AI than it is to be blameworthy for harmful outputs that we may produce with generative AI. This has implications for the issues of meaning and authorship. Generative AI technologies are in important ways “gappy”: they create gaps with respect to meaning and authorship, as well as with respect to responsibility for their outputs.
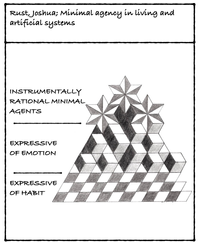
Joshua Rust (Stetson University): Minimal Agency in Living and Artificial Systems
Two innovations characterize the proposed account of minimal agency. First, the so-called “precedential account” articulates a conception of minimal agency that is not grounded in a capacity for instrumental rationality. Instead, I describe a variety of what Rosalind Hursthouse calls “arational action” wherein an agent acts in a certain way because it had previously so behaved under similar circumstances. Second, I consider the extent to which the precedential account applies, not just to a broad swath of living systems, including single-celled organisms, but to two categories of artificial system – social institutions and Large Language Models (LLMs).
Henry Shevlin (Leverhulme Centre for the Future of Intelligence, University of Cambridge): Consciousness, Machines, and Moral Status
In light of recent breakneck pace in machine learning, questions about whether near-future artificial systems might be conscious and possess moral status are increasingly pressing. This paper argues that as matters stand these debates lack any clear criteria for resolution via the science of consciousness. Instead, insofar as they are settled at all, it is likely to be via shifts in public attitudes brought about by the increasingly close relationships between humans and AI users. Section 1 of the paper I briefly lays out the current state of the science of consciousness and its limitations insofar as these pertain to machine consciousness, and claims that there are no obvious consensus frameworks to inform public opinion on AI consciousness. Section 2 examines the rise of conversational chatbots or Social AI, and argues that in many cases, these elicit strong and sincere attributions of consciousness, mentality, and moral status from users, a trend likely to become more widespread. Section 3 presents an inconsistent triad for theories that attempt to link consciousness, behaviour, and moral status, noting that the trends in Social AI systems will likely make the inconsistency of these three premises more pressing. Finally, Section 4 presents some limited suggestions for how consciousness and AI research communities should respond to the gap between expert opinion and folk judgment.
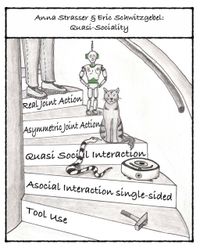
Anna Strasser (DenkWerkstatt Berlin/ LMU Munich) & Eric Schwitzgebel (UC Riverside): Quasi-Sociality: Toward Asymmetric Joint Actions
What are we doing when we interact with LLMs? Are we playing with an interesting tool? Do we enjoy a strange way of talking to ourselves? Or do we, in any sense, act jointly when chatting with machines? Exploring conceptual frameworks that can characterize in-between phenomena that are neither a clear case of mere tool use nor fulfill all the conditions we tend to require for proper social interactions, we will engage in the controversy about the classification of interactions with LLMs. We will discuss the pros and cons of ascribing some form of agency to LLMs so they can at least participate in asymmetric joint actions.
Frederic Gilbert & Alessio Tacca (University of Tasmania): Just Copy-paste Me! Assessing the risks of epistemic dependence on Large Language Models
LLMs are increasingly being employed in epistemic contexts, namely those contexts in which a subject uses LLM outputs in order to fulfill their epistemic goals, such as acquiring justification or increasing their knowledge or understanding. Relying on a LLM system to achieve epistemic goals one is incapable or not willing to achieve by other means (experience, testimony etc.) comes with epistemic risks. In our contribution, we illustrate the gradual progression of what we call the spectrum of epistemological risks, an incremental model of epistemic harms linked with usage of LLMs, starting by casual usages, to reliance, over-reliance, dependence and addiction. Dependence on LLMs seems to be notably potent since LLMs’ outputs are often relied upon uncritically, potentially generating a process of epistemic deskilling. We suggest that increasing knowledge and understanding of how LLMs work and how they sit within the context of users’ epistemic goals is a solution to mitigate epistemically dependent agents’ vulnerability. A thorough analysis of epistemic dependence to LLMs is essential to better understand the epistemic relation between users and language models, but gives also significant insights on whether or not we need even larger LLMs.
Michael Wilby (Anglia Ruskin University ARU) & Anna Strasser (DenkWerkstatt Berlin/ LMU Munich): Situating Machines within Normative Practices: Agency, moral responsibility & the AI-stance
Artificial learning systems increasingly seem to occupy a middle ground between genuine personhood on the one hand, and mere causally describable machine on the other. Such systems are neither wholly lacking mentality, nor wholly possessing it; neither wholly lacking agency, nor wholly possessing it; neither wholly lacking moral responsibility nor wholly possessing it. This lends itself to a host of problems: psychological, ethical, and legal. Under what circumstances, and in what ways, should we treat artificial systems as thinking things, with agency and forms of legal and moral responsibility, which cannot be off-loaded elsewhere?In this paper, we argue for what we call the ‘AI Stance’ (Strasser & Wilby 2023) that is applicable to artificial systems when engaged in interactions with human partners and suggest that taking the AI stance allows for artificial system to be judged blameworthy for their action, and for future interactants with the system to modify their relations with that system in ways that appropriate to that judgement.